こんにちわ。 システム開発部ネットワーク課のsupercontinueです。
はじめに
ゲームサービスをより良いものにしていくためには、ユーザーの行動分析が必要です。
分析するためには、データを収集・加工・可視化(≒集計)する必要があります。
収集
- ゲームのデータをBigQueryにインポートする方法 で説明をしました。
- ユーザーが何かをした時に、1行(以上)のログが記録されます。
加工
- 上記のログを、「1日間」や「新規登録者」や「購入額」などのような分析に適した加工をします。
可視化
- 加工されたデータを表やグラフを使い、分析に適した表現で可視化します。
- 今回はGoogleのデータポータルを使います。
そもそも、何のために・何を・どう分析するのかが重要ですが、それについてはここでは触れません。
以下では、加工・可視化の工程例を説明します。
加工・可視化の工程
基本的な工程は下記となります。
BigQueryでデータセットを作成・選択、加工したデータの結果を格納するテーブルを作成します。
- BigQueryのUIで作成できます。
データを加工・格納するクエリーを作成します。
デイリーでの集計などのため、必要に応じてクエリーをスケジュールします。
- BigQueryでクエリーのスケジュールを作成できます。
データポータルでデータを可視化します。
BigQueryでデータを加工するクエリーの例
下記の構成で説明をします。
my_projectプロジェクト名my_datasetデータセット名app_logログのテーブル名jsonPayload.kpitypeログの種類を示すカラム
DAU
- DAU(Daily Active Users)は、その日にプレイした人の一覧で、人数の合計値は一般的なKPIの一つです。
- DAU一覧は各種の分析を行うにあたり、ソースの1つとすることが多いテーブルです。
DAU一覧
- 集計テーブルは下記です。
| フィールド名 | 種類 | 説明 |
|---|---|---|
| date | DATE | 年月日 |
| uid | INTEGER | ユーザーID |
| ostype | INTEGER | AndroidやiOSなどOS種類を示す数値 |
- 前日のDAUを集計するクエリーは下記のようになります。
- 以下の例では、
jsonPayload.kpitype=23が、プレイしたユーザーのその日最初のログです。 - タイムゾーンに注意する必要があります。ここでは
Asia/Tokyoで集計を行なっています。 - 再試行しやすくするために、集計する直前に結果を格納するレコードを削除しておきます。
DELETE FROM`my_project.my_dataset.dau` WHERE date = DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY);
INSERT INTO `my_project.my_dataset.dau`
SELECT
DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY) AS date,
labels.uid AS uid,
CAST(jsonPayload.ostype AS INT64) AS ostype
FROM `my_project.my_dataset.app_log`
WHERE jsonPayload.kpitype = 23
AND DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY) = DATE(timestamp, "Asia/Tokyo");
DAU合計
- DAU合計値は参照する機会が多いので、あらかじめ算出しておきます。
- OSの種類ごとに合計値を出します。
- 集計テーブルは下記です。
| フィールド名 | 種類 | 説明 |
|---|---|---|
| date | DATE | 年月日 |
| total | INTEGER | DAUの合計ユーザー数 |
| ostype | INTEGER | AndroidやiOSなどOS種類を示す数値 |
- 集計済みの dau テーブルから算出します。
- クエリーは下記のようになります。
DELETE FROM`my_project.my_dataset.dau_sum` WHERE date = DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY);
INSERT INTO `my-project.my_dataset.dau_sum`
SELECT
DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY) AS date,
COUNT(DISTINCT uid) AS total,
ostype AS ostype
FROM `my_project.my_dataset.dau`
WHERE date = DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY)
GROUP BY ostype
ORDER BY ostype;
データポータルでデータを可視化する方法
基本的な流れ
データポータルで「レポート」を作成します。
データソースを追加します。
- 「データの追加」で、BigQueryを選び、データソースを追加します。
- プロジェクト、データセット、表を選びます。
- トップメニューにある「データソースの追加」からも行えます。
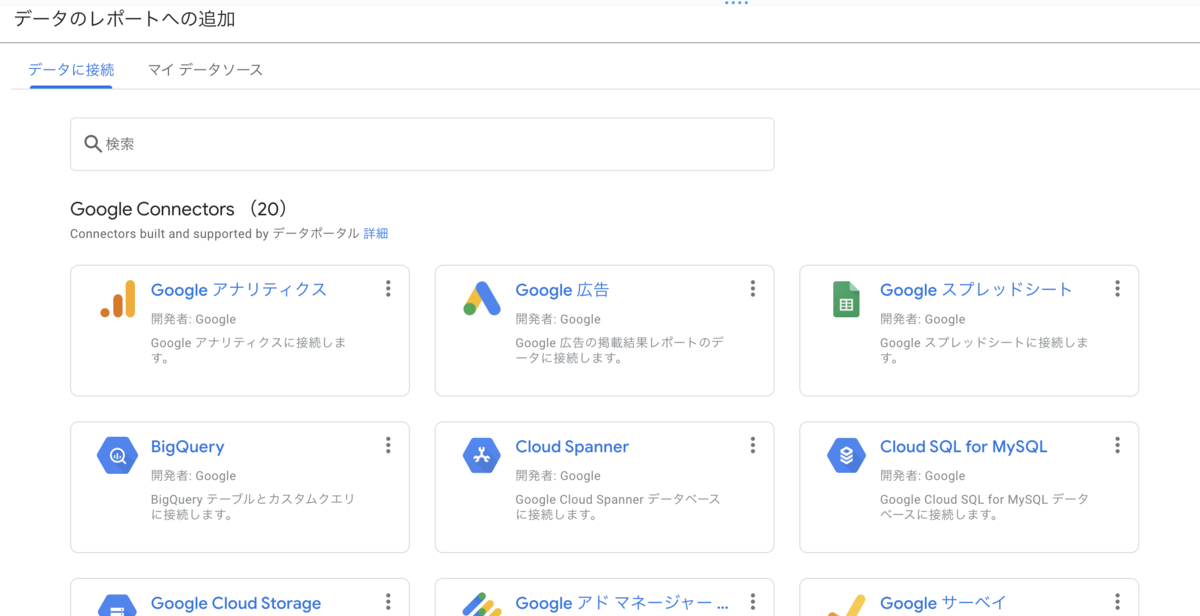
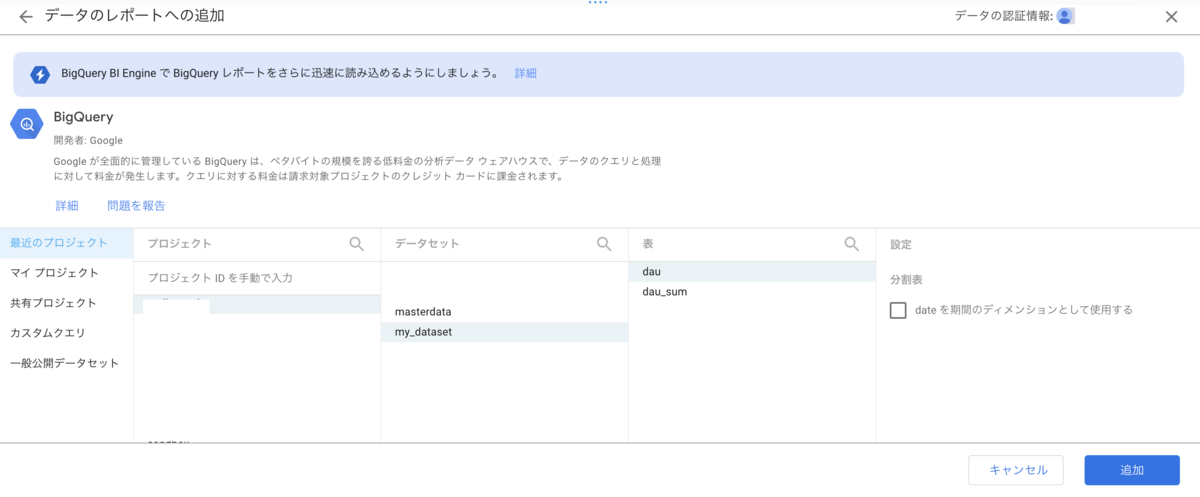
- 「データの追加」で、BigQueryを選び、データソースを追加します。
表やグラフを追加します。
「挿入」からグラフの種類を選びます。

下記のようなグラフが選べます。
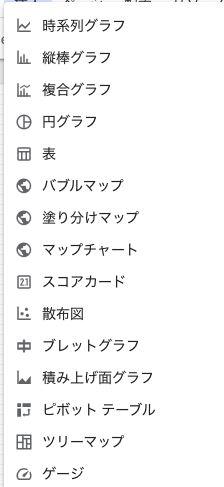
「データソース」を指定します。
- 「ディメンジョン」、「指標」などを指定します。

データソースの扱い方
データポータルではデータソースを使い、データの集計・結合・フィルタなどが可能です。
表現したい内容に応じて、下記のいずれかの方法でデータソースを扱います。
1つのデータソースの内容をそのまま使う。
- 単純な一覧表、そのテーブルだけで集計できる値、集計済みの値のみを表示する場合です。
- 例えば、下記のような日付ごとに集計済みのKPIをグラフで表示したいケースです。

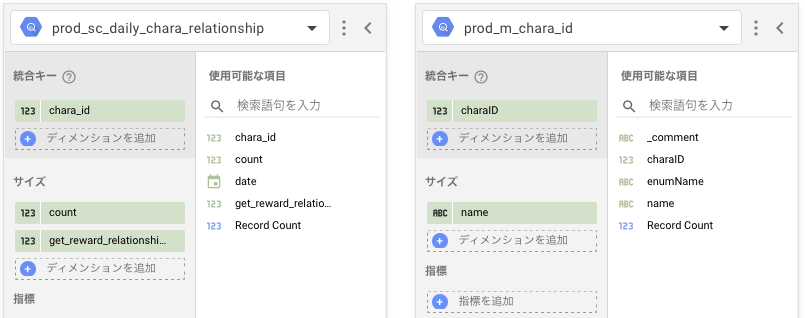
複数のデータソースを結合して使う。
- 複数のデータソースを結合して、新たなデータソースを定義することができます。
- 1つのグラフに複数のデータを表示させたい場合。
- 例えば、同じ日付で、別々のデータ(DAUと継続日数分布など)を表示させたいケースです。
表示用の文字列があるマスターデータを使い、値を文字列へ変換して表示したい場合。
クエリーを実行せずに、複数のデータソースを使ってアドホックな分析をしたい場合。
- 例えば、DAU一覧とプレイ日数一覧と行動数一覧があり、結合して分析をしたいケースです。
- ただし、なるべくBigQueryで結合や加工した集計済みのテーブルを用意する方が、データポータルだけで頑張るよりも効率的と感じます。
グラフの扱い方
グラフは非常に多岐に渡り、設定する情報も多いため、それぞれ必要な時にやりかたを調べるのがいいです。
グラフのスタイルの調整が、最も時間を食います。 最初は見栄えに拘らない方がいいと思います。
エクセルなどに比べ、安全にインタラクティブなレポートを作れるのが、データポータルの強みです。
- フィルタ機能やソート機能をうまく使えるようになると、レポートを見る側の利便性が上がります。
「期間」のフィルタは、データポータルで扱いやすくなっており、DATEの列があれば、勝手に設定してくれます。
- 指標ごとに「期間」の範囲で値を、「合計」するのか「平均」するのかなどを設定する必要があります。たとえば、「新規ユーザー数」は「合計」が適切ですし、「DAU」は「平均」が適切な場合と「最大」のほうが適切な場合があるかもしれません。
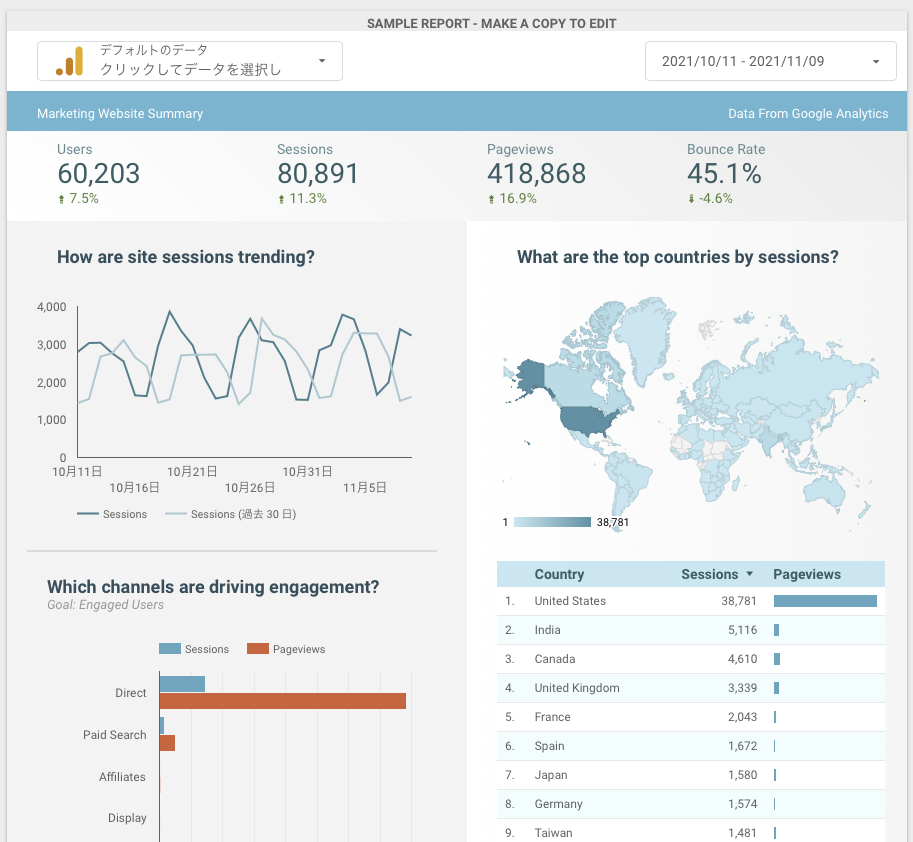
下記にデータポータルのサンプルのレポート画面をあげます。 見栄えには少々手間をかける必要はありますが、このようなレポートが作れます。
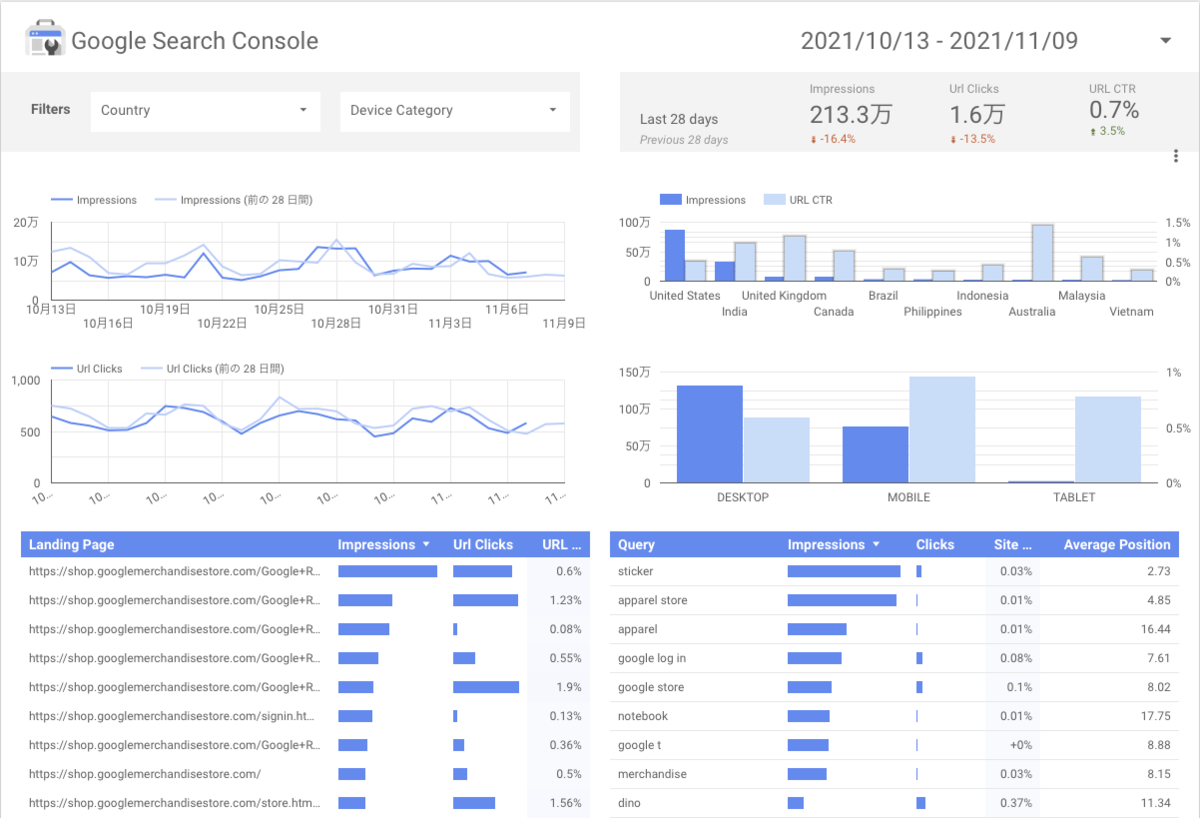
おわりに
BigQueryとデータポータルを使用して、開発コストを抑えて、ゲームのログデータの可視化を行えます。
エクセルなどと異なり、期間や項目などをインタラクティブに変更できるレポートが比較的簡単にできます。
データポータルと同様のサービスであるLookerについても、確認した方が良いでしょう。
リベル・エンタテインメントでは、このような最新技術などの取り組みに興味のある方を募集しています。もしご興味を持たれましたら下記サイトにアクセスしてみてください。 https://liberent.co.jp/recruit/